Détection d’anomalies dans les séries temporelles avec des auto encodeurs LSTM (Keras avec python)
Ce guide vous montrera comment construire un modèle de détection d’anomalies pour les données de séries chronologiques. on va apprendre à utiliser les LSTM et les autoencodeurs dans Keras et TensorFlow 2.
Nous allons utiliser le modèle pour trouver des anomalies dans les prix quotidiens du S&P 500.
Détection d’anomalies
La détection des anomalies consiste à trouver/identifier des événements ou des points de données rares. Parmi ces applications, citons la détection des fraudes bancaires, la détection des tumeurs en imagerie médicale et les erreurs dans les textes écrits.
De nombreuses approches supervisées et non supervisées de la détection des anomalies ont été proposées. Voici quelques-unes de ces approches : One-class SVMs, Bayesian Networks, Cluster analysis, et Neural Networks.
Nous utiliserons un réseau de neurones autoencodeur LSTM pour détecter/prédire les anomalies
Auto encodeurs LSTM
Les réseaux neuronaux auto encodeurs essaient de trouver la représentation des données de leur entrée. L’entrée de l’auto-codeur est donc la même que la sortie ?Pas tout à fait. En général, nous voulons utiliser un codage efficace qui utilise moins de paramètres et de mémoire.
Le codage doit permettre d’obtenir une sortie similaire à l’entrée originale. En un sens, nous forçons le modèle à tirer les caractéristiques les plus importantes des données en utilisant le moins de paramètres possible.
Détection d’anomalies avec des autoencodeurs
Voici les étapes de base de la détection d’anomalies à l’aide d’un auto-encodeur :
- Entraîner un auto-encodeur sur des données normales (sans anomalies)
- Prenez un nouveau point de données et essayez de le reconstruire en utilisant l’auto-encodeur.
- Si l’erreur (erreur de reconstruction) pour le nouveau point de données est supérieure à un certain seuil, nous considérons l’exemple comme une anomalie.
S&P 500 Index Data
Nos données sont les prix de quotidiens de l’index S&P 500 de 1986 à 2018.
Le S&P 500 est un indice boursier basé sur 500 grandes sociétés cotées sur les bourses aux États-Unis (NYSE ou NASDAQ). L’indice est possédé et géré par Standard & Poor’s, l’une des trois principales sociétés de notation financière. Il couvre environ 80 % du marché boursier américain par sa capitalisation. C’est un indice sans dividendes.(Wikipédia)
Les données ne contiennent que deux colonnes,la date et le prix .Nous allons les télécharger et les charger dans un DataFrame:
Jetons un coup d’œil au prix quotidien :

Prétraitement
Nous allons utiliser 95 % des données et entraîner notre modèle sur celles-ci :
Ensuite, nous allons redimensionner les données en utilisant les données de training et appliquer la même transformation aux données de test :
Enfin, nous allons diviser les données en sous-séquences. Voici la petite fonction d’aide pour cela :
Nous créerons des séquences avec des données historiques de 30 jours
Auto encodeur et LSTM dans Keras
Notre Auto encodeur doit prendre une séquence en entrée et sortir une séquence de la même forme. Voici comment construire un modèle aussi simple dans Keras :
La couche de RepeatVector répète simplement l’entrée n fois. L’ajout de return_sequences=True dans la couche LSTM lui permet de retourner la séquence.
Enfin, la couche TimeDistributed crée un vecteur dont la longueur est égale au nombre de sorties de la couche précédente. notre premier Auto encodeur LSTM est prêt pour l’entraînement.
L’entraînement du modèle n’est pas différent de celui d’un modèle LSTM ordinaire :
Evaluation
Nous avons entraîné notre modèle pendant 10 époques avec moins de 8000 exemples. Voici les résultats :

Trouver des anomalies
Néanmoins, nous devons détecter les anomalies. Commençons par calculer l’erreur absolue moyenne (EAM) sur les données d’apprentissage.
Jetons un coup d’œil à l’erreur :

Nous choisirons un seuil de 0,65, car peu de pertes sont supérieures à ce seuil. Lorsque l’erreur est supérieure à ce seuil, nous déclarons que cet exemple est une anomalie
Calculons la MAE sur les données de test :
Nous allons construire un DataFrame contenant la perte et les anomalies (valeurs au-dessus du seuil) :

Il semblerait que nous ayons bien seuillé les valeurs extrêmes. Créons un DataFrame en utilisant uniquement celles-ci :
anomalies = test_score_df[test_score_df.anomaly == True]Enfin, examinons les anomalies constatées dans les données de test :
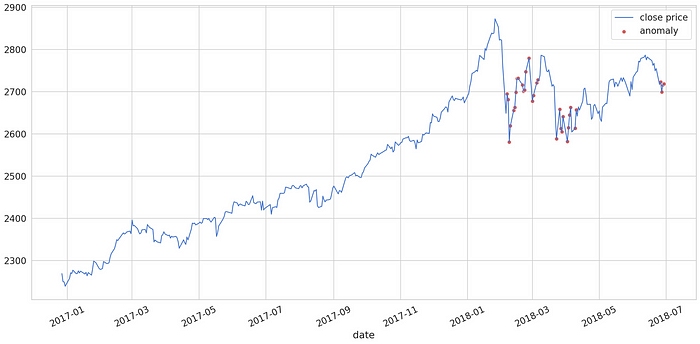
Les points rouges (anomalies) couvrent la plupart des points présentant des changements brusques du prix de clôture.
Vous pouvez jouer avec le seuil et essayer d’obtenir des résultats encore meilleurs.
